
Vehbi Neziri
PhD in Computer Science
Contribution in building the Albanian Language Lemmatizer
ABSTRACT
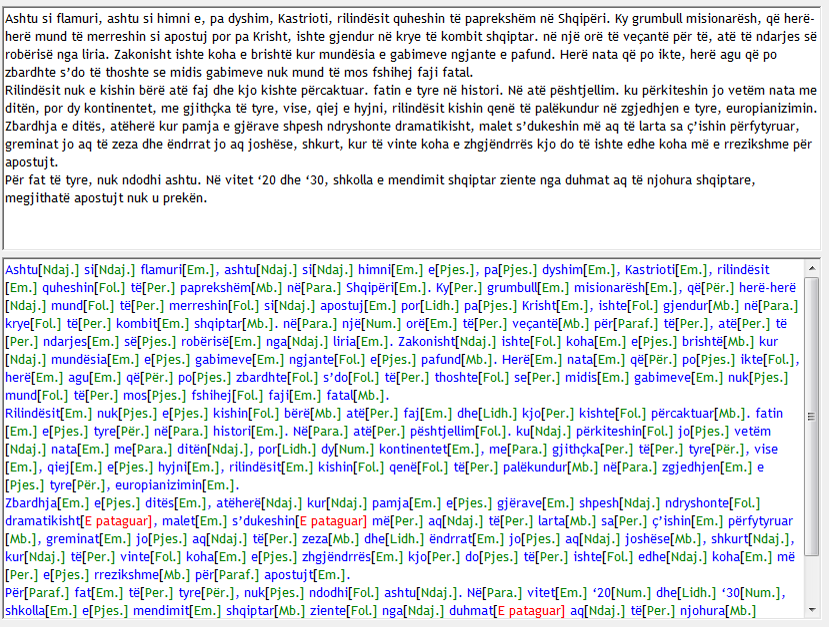
Përmbledhje: Zhvillimi i hovshëm i teknologjive gjuhësore ka ndryshuar gati plotësisht rolin e morfologjisë klasike duke mundësuar që studimi i trajtëformimit, formave të ndryshme të fjalëve të lakueshme: emrave, mbiemrave, përemrave, numërorëve, dhe i fjalëve të zgjedhueshme: foljeve, të bëhet shpejt dhe pothuajse krejtësisht në mënyrë automatike. Shumë gjuhë të botës sot kanë lematizuesit automatik për lematizimin (angl. lematization) e fjalëformave të korpusit përkatës të gjuhës së tyre duke i sjellë fjalët e tij në leksemat e tyre përkatëse a në fjalëformën përfaqësuese (lemën) e cila zakonisht jepet në fjalor. Lematizuesit përveç rolit të tyre në nxjerrjen e lemave gjerësisht janë duke u përdorur edhe për gjetjen e fjalëve të reja në korpuset tekstore të specializuara dhe ato të përgjithshme. Qëllimi i këtij punimi është të tregojë rrugën e ndërtimit dhe të vërtetojë efikasitetin e lematizuesit të gjuhës shqipe i cili është në gjendje të bëjë saktë e shpejtë lematizimin e trajtëformave të fjalëve të gjuhës shqipe standarde dhe i cili do të jetë mjaft inteligjent të vetëmësohet duke i lematizuar trajtëformat e shqipes jo standarde. Ndërtimi i lematizuesit është bërë me komponentën e vetëmësimit për shkak të teksteve të vjetra të shqipes dhe përdorimit gjithnjë në rritje të fjalëve të reja dhe fjalëformave të tyre.
Fjalët çelës: lematizim, lemë, fjalor, trajtëformë, gjuhë shqipe, korpus-tekstor
Key-words: lemmatization, lemma, vocabulary, token, Albanian language, text-corpus